
Les réseaux de neurones modernes, dotés de milliards de paramètres, sont si surparamétrés qu’ils peuvent « surapprendre » même des données aléatoires sans structure. Pourtant, entraînés sur des jeux de données ayant une structure, ils en apprennent les caractéristiques sous-jacentes. Comprendre pourquoi la surparamétrisation n’annule pas leur efficacité est un enjeu fondamental de l’Intelligence Artificielle (IA). Deux chercheurs, Andrea Montanari (Stanford) et Pierfrancesco Urbani (IPhT) proposent que l’apprentissage des caractéristiques sous-jacentes et surapprentissage peuvent coexister pendant l’entraînement, mais à des échelles de temps distinctes.
L’informatique prend ses racines dans les travaux pionniers d’Alan Turing. Il conçut une machine programmable capable d’évaluer automatiquement des fonctions complexes à partir d’une entrée initiale. Très important : les instructions pour ces opérations, appelées algorithme (ou logiciel), doivent être fournies extérieurement à la machine et modifiées lorsque la tâche/le calcul change. Cette séparation entre la « machine » et les « instructions » est l’architecture qui contrôle le fonctionnement des ordinateurs portables, smartphones et autres appareils via des codes/programmes/applications.
Un changement de paradigme a lieu dans les années 1950 lorsque des chercheurs suggèrent une architecture d’algorithmes à but ouvert qui apprendrait les instructions nécessaires directement à partir d’un vaste jeu de données d’entraînement. Prenons l’exemple d’un système qui traduit du texte d’une langue à une autre. Une façon de procéder est de coder un algorithme qui traduit chaque mot d’une langue à l’autre et réorganise les mots selon la syntaxe de la nouvelle langue. Cependant, les systèmes modernes fonctionnent en trouvant leur propre algorithme pour traduire le texte de manière autonome à partir d’un vaste ensemble d’exemples de textes traduits. Ceci est réalisé sans aucune notion externe de syntaxe ou de vocabulaire fournie au système. C’est l’essence même de l’apprentissage automatique (machine learning) et des réseaux de neurones.
Les réseaux neuronaux artificiels (ANN) sont des systèmes informatiques où un très grand nombre de paramètres ajustables, appelés poids, sont automatiquement ajustés (optimisés) durant l’entraînement pour apprendre les fonctions mathématiques complexes permettant d’exécuter une tâche donnée.
La compréhension théorique des réseaux simples s’appuie sur la théorie de l’apprentissage statistique. Un pilier central de cette théorie est l’idée que les réseaux sont censés fonctionner efficacement lorsque (grossièrement) leur complexité d’ajustement (par exemple, le nombre de poids) reste faible par rapport à la quantité de données d’entraînement, favorisant ainsi le modèle efficace le plus simple. C’est essentiellement une forme informatique du rasoir d’Occam.
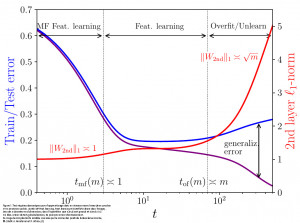
Une crise théorique majeure débuta il y a environ quinze ans lorsque les réseaux neuronaux « profonds » (deep neural networks), une classe de fonctions très complexes utilisées pour l’optimisation, montrèrent empiriquement une grande efficacité même sur des tâches simples. C’était surprenant car ces modèles ont souvent plus de poids que d’exemples d’entraînement, une situation généralement appelée surparamétrisation : ils sont si complexes qu’ils peuvent s’ajuster pour reproduire même des données aléatoires totalement dépourvues de structure (on parle dans ce cas de surapprentissage).
Malgré cela, ces modèles apprennent les caractéristiques latentes des données ayant une structure (feature learning) et sont donc considérés comme généralisant bien. Comprendre pourquoi la surparamétrisation n’affecte pas — et si elle est en réalité bénéfique pour — les performances des réseaux neuronaux modernes est devenu un problème central au cœur des fondements de l’IA et des paradigmes d’apprentissage en général.
Dans un travail récent, accepté comme contribution orale à la conférence NeurIPS 2025, Andrea Montanari (Université de Stanford) et Pierfrancesco Urbani (IPhT) proposent une solution à cette énigme. En combinant des techniques innovantes de physique théorique et une analyse statistique rigoureuse, ils montrent que le surapprentissage et l’apprentissage de caractéristiques coexistent dans les réseaux surparamétrés mais apparaissent à des moments différents de la dynamique d’entraînement (phénomène dit d’émergence d’une séparation des échelles de temps). Le découplage dynamique résultant entre apprentissage des caractéristiques et surapprentissage émerge de l’interaction entre l’algorithme d’entraînement et l’architecture des réseaux, les modèles plus grands présentant une séparation temporelle plus importante. Étant donné que l’apprentissage des caractéristiques survient avant le surapprentissage, ce scénario suggère un mécanisme fiable expliquant pourquoi et comment de vastes réseaux neuronaux surparamétrés fonctionnent.
Ce travail ouvre la voie à une meilleure compréhension de la dynamique d’entraînement
des modèles d’apprentissage automatique modernes. Le scénario d’apprentissage correspondant pourrait également trouver des applications dans d’autres systèmes qui ont besoin d’extraire des informations et de s’adapter en conséquence, tels que les systèmes biologiques.
[1] Andrea Montanari and Pierfrancesco Urbani (2025) Dynamical Decoupling of Generalization and Overfitting in Large Two-Layer Networks. « The Thirty-ninth Annual Conference on Neural Information Processing Systems ». https://openreview.net/forum?id=ImpizBSKcu. https://arxiv.org/abs/2502.21269.